Knowledge Representation & Reasoning
3. KR&R within perception-action loops
3.1. Linking representation to perception and motion
- proposing suitable representations of motions that enable us to combine knowledge representation and reasoning with control engineering, cognitive psychology, and robot learning;
- maintaining and acquiring environment and object representations that are detailed enough for object manipulation; and
- maintaining and updating the symbolic representations by the robot perception system.
Representation and reasoning about motions
Let
us first look at suitable representations for robot body motions and
their physical effects. To develop such representations we can take
inspiration of how humans accomplish their manipulation actions through
the learning, planning, and execution of body motions, which is
intensively investigated in a research field that Prinz, 2013 call
action science. Action science lies in the intersection of several
research disciplines including cognitive psychology, cognitive
neuroscience, and sport science. These research threads contribute to
the representation and reasoning about actions as they investigate more
detailed and realistic models of manipulation actions.For example, Flanagan, 2006 propose a widely used conceptual model for representing and reasoning about the motions that constitute human manipulation actions. This model is depicted in the previous chapter. In this model the body motions of manipulation actions are composed of motion phases. For example, fetching and placing an object is composed of a reaching, a lifting, a transport, and a release phase. Each of these motion phases has a motion goal. The goal of the reaching phase is that the object is grasped, of the lifting phase that the object is lifted off the supporting surface, of the transport phase that the object is at the destination, and of the releasing phase that the object has left the hand. The transitions between the motion phases are so-called force-dynamic events (Siskind, 2001). The force-dynamic events, which also cause distinctive perceptual events in the perceptual system of the robot agent are the contact of the hand with the objects, the hand feeling the gravity of the object, the collision of the object with the destination surface, and the hand losing the grip of the object. The individual motion phases also have knowledge preconditions. When starting the reaching motion the robot must have decided on the target pose, when starting the lifting motion the robot must have committed to a holding pose, and so on.
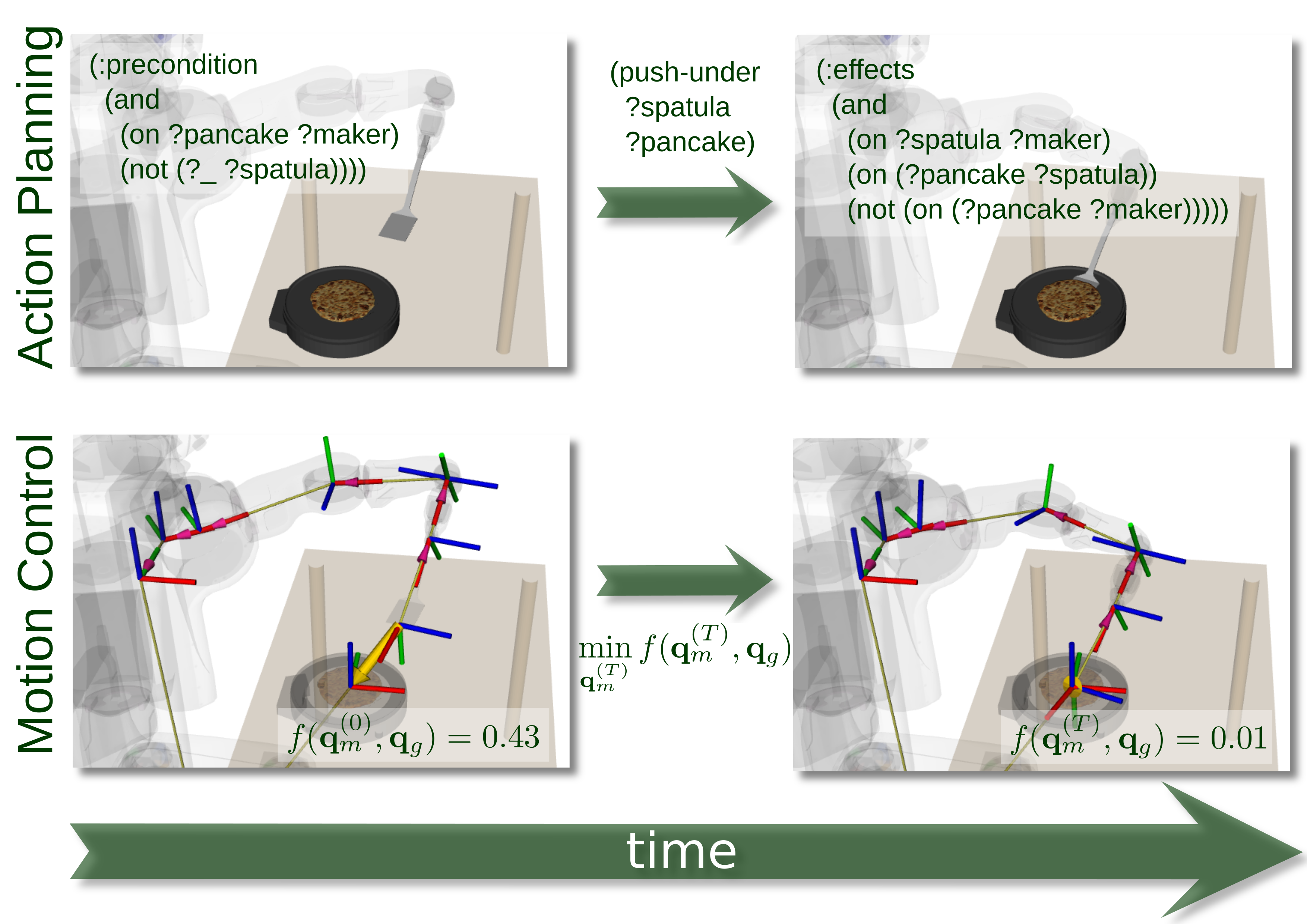
Fig. 1: Comparing the state transition system model with the constraint- and optimization-based control model of manipulation actions.
Another
approach to represent the manipulation actions at the motion level is
to represent the conceptual model underlying the constraint-and
optimization-based control frameworks (Khatib, 1987; Smits, 2009) In
constraint- and optimization-based control the bodies of robot agents
are represented as chains of control frames (6D poses of key conrol
points of the robot). Figure 1 compares
the state transition model with the constraint- and optimization-based
control model. While the logic approach represents the objects and
effects, the control approach specifies constraints and objectives on
motions. Therefore, the semantics of the manipulation actions, in
particular the causal relation between motion parameterization and their
physical effects, has to be encoded into the constraints and objectives
for the motions.
Knowledge-enabled robot programming
When
applying the Flannagan model the task of reasoning is to infer the
motion parameters for the individual motion phases and in constraint-
and optimization-based control the reasoning system has to infer the
motion constraints and objective functions to be optimized. This can be
accomplished through knowledge-enabled robot programming.
In the
knowledge-enabled programming style programmers equip robots with a
combination of generalized action plans and a knowledge base of general,
modular knowledge pieces. The basic idea of knowledge-enabled
programming is to separate knowledge from the control program and to
modularise it into small broadly applicable chunks, such as "grasp
objects by their handles'', "hold filled containers upright'', "do not
squeeze breakable items too hard'', etc. The program would ask: "How
should I pick up the object in front of me?''. A reasoning mechanism
would then collect the relevant knowledge units and combine them in
order to propose the appropriate grasp. The primary advantage is that
these knowledge pieces can be collected and that they can be reused by
other robots accomplishing different tasks with different objects in
different environments (Pratt, 2015). This reuse of generalized
knowledge can, therefore, drastically accelerate the realisation of new
robot applications. Figure~\ref{fig:generalized-knowledge} shows
examples of such generalized knowledge chunks, which can be conveniently
stated as logical axioms.
This idea of leveraging generalized plans for manipulation actions is also supported by a number of cognitive scientists including Schmidt (Drescher, 1991) suggest that movements within a class, such as fetch and place and pouring, share the same order of sub-movements and their relative timing. If these programs are to be executed in different contexts they are called generalized motion programs (or motion schemata) and include variable parameters (e.g., coordinates, body poses, timing, forces) are to be specified to the program. The parameterizations define the details of the movement and how it is executed for particular objects in particular contexts for different purposes. These generalized motion programs are called generalized motion plans if they cannot only be executed but also reasoned about and modified at execution time.

Fig. 2: A generalized motion plan for a pouring action.
Figure
2 show a generalized motion plan for pouring
actions. The plan consists of the signature of the plan and the body of
the plan. The signature includes the name of the plan, which is pour and the formal parameters names theme, source, and dest specifying
the destination of the theme to be poured out of the source container.
The formal parameters are typed: the theme is some substance, the source
is a container object that contains the theme, and the destination is a
location.
The power and
elegance of knowledge-enabled programming comes from facilitating the
application and combination of relevant knowledge pieces for specific
manipulation tasks. This enables robot agents to accomplish manipulation
tasks in new contexts much more competently, flexibly, and robustly.
(Note: As Pratt, 2015 puts it: "Robots are already making large
strides in their abilities, but as the generalisable knowledge
representation problem is addressed, the growth of robot capabilities
will begin in earnest, and it will likely be explosive. The effects on
economic output and human workers are certain to be profound.'')
Consider
again the task of picking up an object. Instead of implementing the
knowledge of how to pick up an object as a piece of code tailored for
the respective context the knowledge of how to pick up objects is
decomposed into a collection of generalized knowledge pieces as listed
in Figure \ref{fig:generalized-knowledge}. This way the knowledge pieces
can be applied to different robots, objects to be picked up, the tasks
for which the object are to be picked up, and the scenes in which the
objects are to be picked up.

(perform
The action description is vague or underdetermined because many pouring behaviors are possible executions of the action description. In Figure \ref{fig:making-popcorn} we have already seen two of them: the one-handed pouring of the popcorn from the bowl into the pot (upper row right) and the pouring of the popcorn from the pot onto the plate. Thus, in order to transform the underdetermined action description into a motion specification that can be executed by the generalized motion plan, the robot agent has to make a number of reasoned decisons based on current context possibly at planning or execution time. Examples of such decisions are which popcorn is meant and how much? The robot also has to choose a plate that is unused, clean, and has enough capacity.
robot has to infer the key movement constraints that ensure that the pot will not fall down, the popcorn on the plate and not spilled on the table including to hold the pot with two hands by its handles and
horizontally, to tilt the pot holding it in the right height and centered above the plate, and so on.
flexibility has to be paid for with the requirement of broader and deeper understanding of intuitive physics and the ability to regress effects into the motions that can achieve them.