Knowledge Representation & Reasoning
3. KR&R within perception-action loops
3.2. Reasoning for object manipulation
We have just seen the kinds of refinements of action descriptions that make the context-specific execution of underdetermined action descriptions possible. So, let us now look at the knowledge representation and reasoning that can inform these refinements. The situation calculus representation we have discussed in the previous section cannot provide the necessary reasoning because of its use of action models that assert that actions cause the effects specified in the models if the preconditions of the actions are satisfied, which is only valid if the effects are independent of how actions are executed.
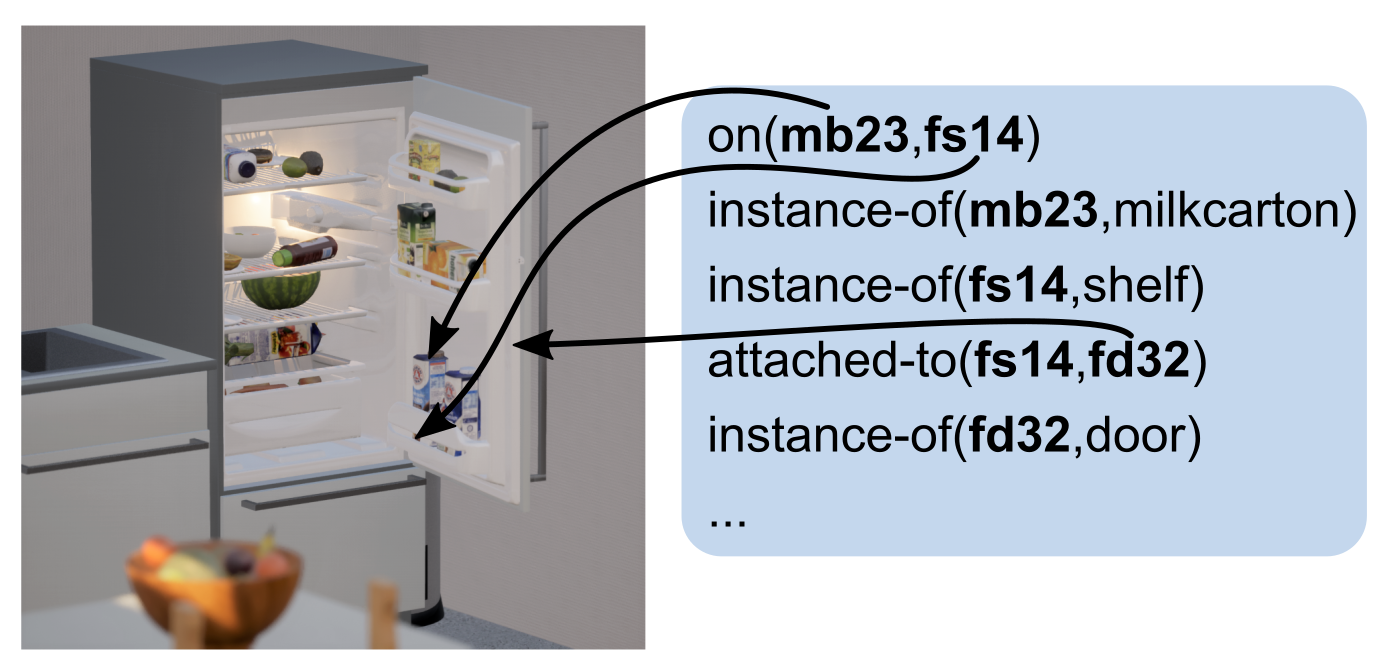
Fig. 1: Typical representation of a scene inside a refrigerator using predicate logic.
When robots execute actions the physical effects of the actions depend on how the actions are executed and what the specific action context is. In recent years more detailed representations of objects, environments, robots, and tasks have gained a lot of momentum. Reasons are advances in in representation learning in deep networks, which allow the automated learning of task-specific representations, and the ones in simulating and rendering virtual reality environments for computer games and other applications.
In this section we will look at the combination of logic representations with the ones used by simulation and rendering engines to enable robot agents to reason about how to move their bodies to accomplish underdetermined action descriptions. To do so, we will look at the problem of picking up a milk box from the refrigerator.
In predicate logic we can represent state of affairs such as entity mb23 is a milkbox located on a shelf that is attached to the door of the fridge. This state of affairs is depicted in Figure 1. If we want to represent the scene in more detail including the structure, the geometry, the appearance, the content, the physical properties, and the articulation of the objects in the environment the knowledge base becomes huge and difficult to reason with.
Representations with the necessary levels of detail have been successfully developed in modern virtual reality technology, in which huge realistic environments are represented very comprehensively and very detailed and physically simulated and rendered in real time and with currently available computing power. For example, already in 2015 the Unreal game engine showed the technology demonstration "a boy and his kite'', which featured realistic physics-based rendering of a 100 square miles environment with 15 million pieces of vegetation, realistically moving animals, and physics-enabled animation of a kite flying in changing wind conditions in real time at 30fps.
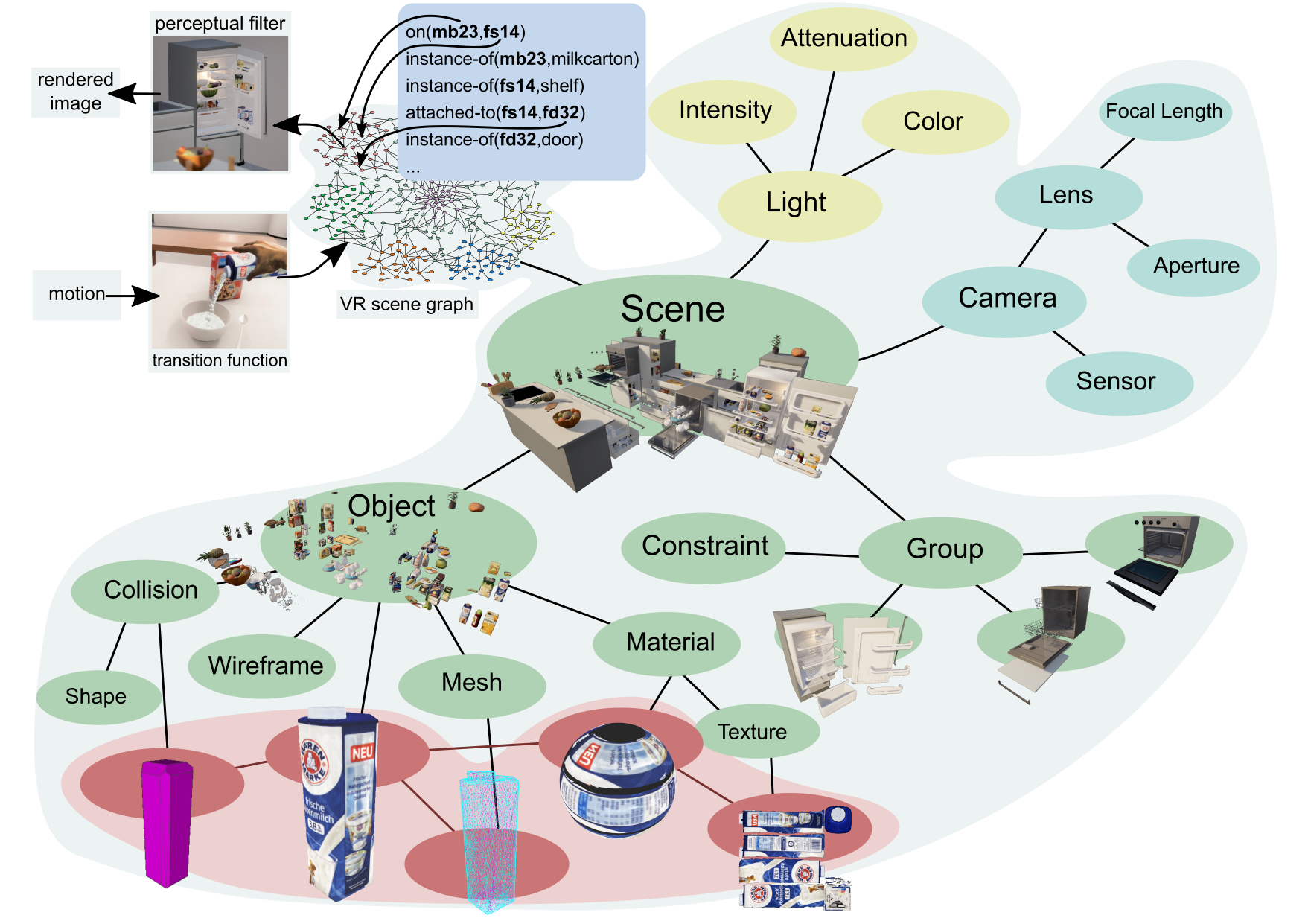
Fig. 2: Linking symbolic names of entities to nodes in scene graphs that represent these entities. The subtrees of the nodes contain the detailed representations of entities that are needed to infer context-specific paratmeterizations of actions.
Virtual reality systems represent environments as scene graphs, that are specifically designed data structures that contain all the information needed to render images and animations of 3D scenes. The scene graph is a tree-like data structure where the nodes represent subscenes and the child relations from a node p to the nodes  state that the scene p contains all subscenes . The leaf nodes, called shape nodes, represent the geometry, appearance, lighting, texture, surface attributes, and material of the respective physical entity. The bodies of the entities are typically CAD models or meshes. The inner nodes hold a group or composition of children nodes that might be constrained by physical relations such as attachment, support, and articulation. Also children nodes might represent the subscene at different levels of detail based on distance to viewer. Or, they might represent different states of of a subscene like a container being open or closed. For rendering purposes the inner nodes might also contain light sources and local cameras. The inner nodes also include transformations that move, rotate, and scale the subscenes within its own reference frame.
state that the scene p contains all subscenes . The leaf nodes, called shape nodes, represent the geometry, appearance, lighting, texture, surface attributes, and material of the respective physical entity. The bodies of the entities are typically CAD models or meshes. The inner nodes hold a group or composition of children nodes that might be constrained by physical relations such as attachment, support, and articulation. Also children nodes might represent the subscene at different levels of detail based on distance to viewer. Or, they might represent different states of of a subscene like a container being open or closed. For rendering purposes the inner nodes might also contain light sources and local cameras. The inner nodes also include transformations that move, rotate, and scale the subscenes within its own reference frame.
Scene graphs are highly optimized and facilitated by very fast and efficient algorithms for storing, managing very complex and detailed scenes, for retrieving information from them, for visual rendering them and simulating the physical effects of actions performed in the scenes.
Using scene graphs, we can realize detailed and multi resolution representations by linking symbolic entity names to the nodes in the scene graphs they represent, as it is shown in Figure 2. This way the KR&R system can make the detailed information available that is needed for the contextualization such as the geometry of the milk box, its parts, and its visual appearance. In the scene graph the milkbox is implemented as a subtree that contains all the data and computation mechanisms needed to realistically render and simulate the milkbox. This level of detail is sufficient for inferring body motions.
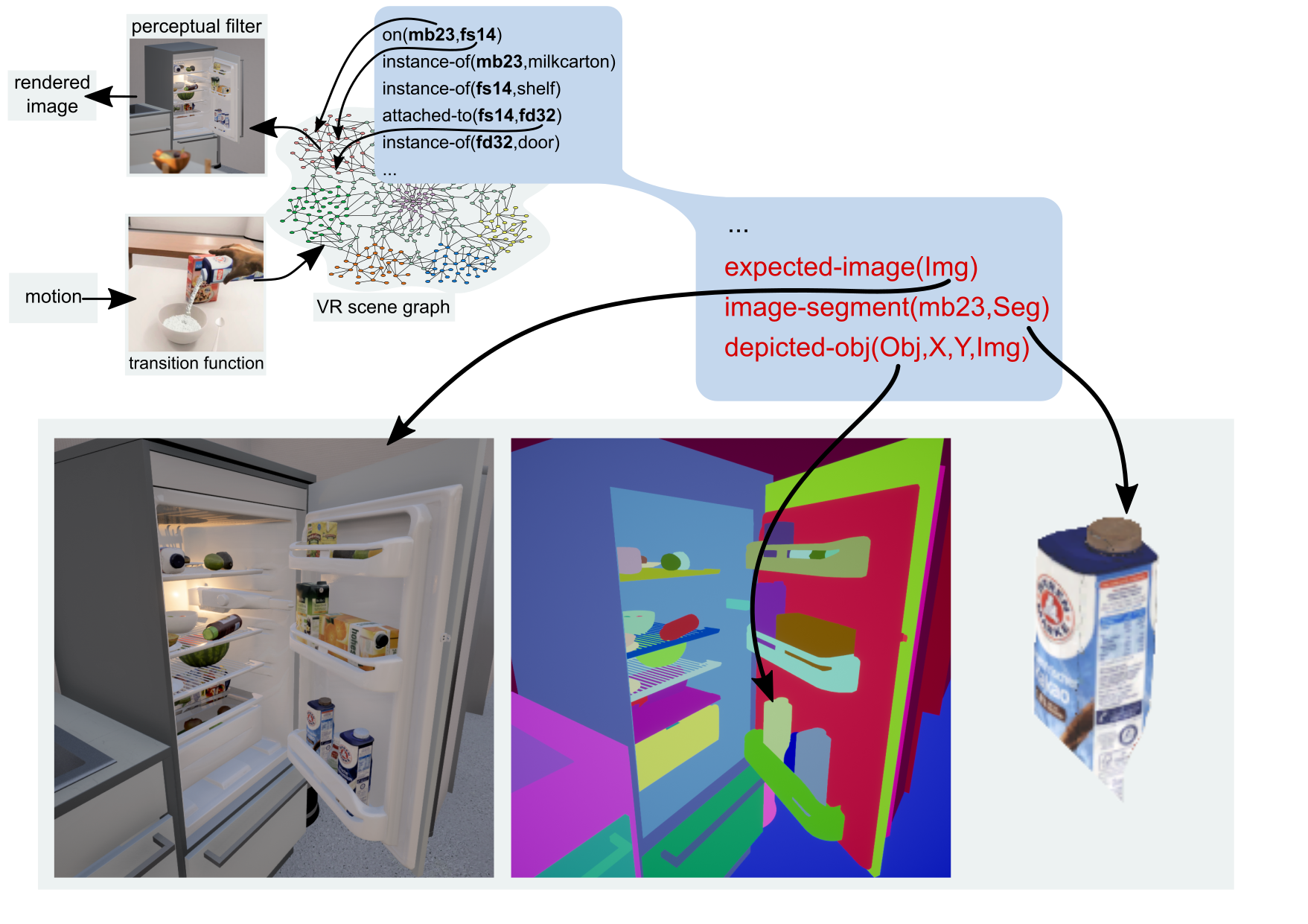
Fig. 3: Defining new predicates by computing their truth values through retrieving information from scene graphs and using the rendering process of the virtual reality environment.
Using the scene graphs, we can realize virtual knowledge bases using symbolic predicates that compute their truth values through procedural attachments. As shown for example in Figure 3, we can define a predicate expected-camera-image(Img), which is true for the image Img that the robot expects to see given its belief state. When the KR\&R reasoner tests the truth value of the statement expected-camera-image(Img) it represents the beliefs of the robot as a scene graph, creates a virtual camera that matches the technical specification of its own camera, places the camera acording its pose estimates, renders an image, and binds the image to the symbolic variable Img. A predicate image-segment(Obj,Segs,Img) relates each object Obj in an image Img with the image segments Segs depicting it by asserting that all other objects are invisible. Thus, using the detailed representations of scene graphs and the rendering and simulation capabilities of virtual reality engines the reasoning capabilities of KR&R frameworks can be substantially improved.